성능향상을 위해 도입한 Springboot Webflux, 그리고 R2DBC 였지만 다량의 데이터를 INSERT할 때 성능이 훨씬 떨어지는 부분을 발견했습니다. 이번 포스트에서는 어떤식으로 성능에 대해 고민 하고 개선 할 수 있었는지 정리 해 보고자 합니다.
주니어 개발자로써 항상 부족함을 많이 느끼고 있기에, 추가적인 의견이나 잘못된 점에 대한 지적은 항상 환영입니다.
Batch Insert란 ?
Batch Insert라는 개념은 어려울 것이 없습니다.
예를 들어, 3건의 INSERT 쿼리를 날린다고 했을 때 아래처럼 3개의 INSERT문을 날리는 것이 아니라,
INSERT INTO TestTable(c1, c2) VALUES(v1, v2);
INSERT INTO TestTable(c1, c2) VALUES(v3, v4);아래처럼 하나의 쿼리로 처리하는 것을 Batch Insert 라고 합니다.
INSERT INTO TestTable(c1, c2)
VALUES(v1, v2), (v3, v4);대량의 데이터를 처리할 때에는 당연히 Batch Insert 방식을 사용하는 것이 성능적으로 우월합니다.
R2DBC Batch Insert 성능
Webflux는 Reactive하게 작동하기 때문에 WebMVC보다 성능이 좋을 것이라는 것이 당연한 기대인 것처럼, Reactive한 R2DBC를 선택 했을 때도 성능이 개선되길 기대했습니다.
하지만, R2DBC를 이용해 Batch Insert를 진행 할 때 그렇지 않다는 사실을 발견했습니다.
제가 짰던 코드 방식을 보며 어떤 문제가 있었고, 어떻게 성능을 개선 했는지 알아 봅시다.
테스트 환경
저는 초당 10*100건의 데이터를 수신하고 이를 buffer에 저장한 후 buffer가 정해진 사이즈를 다 채우거나, 일정시간이 지나게 될 때 한번에 mariaDB에 넣는 로직을 개발하기 위해 bulk insert의 성능에 대해 고민하기 시작했습니다.
따라서 사용 DB는 mariaDB를 이용했으며, 반복문을 통해 해당 buffer에 데이터를 쭉 밀어넣는 방식으로 테스트를 진행 했습니다.
1. SaveAll 방식 - 10,000건: 17초
가장 처음 접근 했던 방식은 R2DBC repository에서 제공하는 saveAll() 메소드를 이용했던 방식입니다.
batch Insert로 쿼리가 생성 될 것이라 예상 했던 것과 달리, 각각의 Insert문이 생성되는 것을 볼 수 있었습니다.
private Flux<TestEntity> batchInsert(Flux<TestEntity> testFlux) {
long startTime = System.currentTimeMillis();
return testRepository.saveAll(testFlux)
.doOnComplete(() -> {
long endTime = System.currentTimeMillis();
long elapsedTime = endTime - startTime;
log.info("Time consumed by bulkInsertCarStatus: {} milliseconds", elapsedTime);
});
}
당연하게도, 성능은 너무 느렸습니다.
10000건의 데이터를 Insert하는데 총 17초가 걸렸습니다.

이때까지만해도 뭐 batchInsert로 하면 금방 해결 되겠지 생각 했습니다.
2. Parameterized Statement 방식 - 10,000건: 10.5초
r2dbc 에서 batch insert를 할 때에는 statement의 add(), bind()를 이용하는 방식을 이용할 수 있다는 부분을 찾았습니다.
(r2dbc 공식문서 - statements.batching)
조금 귀찮아지긴 했지만, 금방 r2dbc에서 말하는 방식으로 개발 할 수 있었습니다. 대략적인 코드는 아래와 같았습니다.
private Flux<TestDTO> flushDatas(List<TestDTO> testDtoList) {
return databaseClient.inConnectionMany(connection -> {
Statement stmt = connection.createStatement(this.initSql.toString());
this.bindAllListValues(stmt, testDtoList, TestDTO.class);
long startTime = System.currentTimeMillis();
return Flux.from(stmt.execute())
.flatMap(result -> (Flux<TestDTO>) result.map((row, metadata) -> {
return TestDTO.builder()
.id(null)
.build();
}))
.doOnComplete(() -> {
long endTime = System.currentTimeMillis(); // Capture end time
long elapsedTime = endTime - startTime; // Calculate elapsed time
log.info("Time consumed by bulkInsertCarStatus: {} milliseconds to insert {} items.",
elapsedTime, carStatusList.size());
});
});
가장 먼저 체크했던 부분은 '진짜 batch insert 방식으로 동작하느냐' 였고, 내가 원하는 방식으로 동작함을 확인 하였습니다.
분명 성능 또한 이전의 saveAll 방식에 비해 많이 개선되었지만, 여전히 너무 느렸습니다. 테스트 결과는 아래와 같았습니다.
parameterized statement batch insert 성능 테스트 결과 - 10,000건 기준
buffer사이즈는 한번의 쿼리에 몇 건의 데이터를 Insert 하는 지를 의미합니다.
예를 들어, 버퍼 사이즈가 1,000건 인데 총 10,000건을 Insert한다면 10개의 쿼리가 생성 될 것입니다.
아래 테스트 결과는 총 10,000건의 데이터를 각기 다른 버퍼 사이즈로 Insert 했을 때 소요된 시간에 대한 표입니다.
| buffer 사이즈 | 소요시간(ms) |
| 100 | 11,890ms |
| 500 | 10,684ms |
| 1000 | 10,603ms |
| 2000 | 10,555ms |
| 5000 | 12,181ms |
| 10000 | 19,062ms |
buffer 사이즈에 따라 성능이 달라지고, 몇 번의 테스트 결과 10,000건을 Insert하기 위해서는 buffer 사이즈를 2000개로 정하는 것이 좋다고 판단 했지만, 여전히 현재 개발 중인 프로젝트에서 사용하기 부적절한 성능을 보여주고 있었습니다.
3. Index 조정 - 10,000건: 10.3초
사내에서 batch insert 테스트 중인 테이블은 꽤나 많은 칼럼과 하나 이상의 index를 가지고 있었습니다.
설계 단계에서 빠른 검색을 위해서 index를 설정 했으나, 이 부분이 Insert 할 때 문제가 될 수 있다고 하여 불필요해 보이는 부분을 다시 수정했지만, 크게 유의미하게 성능이 개선 되지 않았고, 심지어 모든 인덱스를 제거하고도 성능은 10초 이하로 내려가지 않았습니다.
4. Raw Query 방식 - 100,000건 : 10.05초
납득할 수 없는 성능에 열심히 구글링을 한 결과 r2dbc 깃헙 이슈에서 다음과 같은 글을 찾을 수 있었습니다. (r2dbc batch issue)
이슈 등록은 2019년 12월 19일 이었지만, 최근까지 업데이트가 되고 있는 따끈따끈한 이슈였습니다.
해당 이슈의 요약은 아래와 같았습니다.(직접 읽어 보는 것을 추천합니다.)
데이터베이스에서 Batch Insert를 하는 방법은 크게 두가지가 있다.
1. parameterize하지 않고, SQL operations을 이어 붙이는 방식
2. bind를 통한 prepared statements를 사용하는 방식
(참고로 내가 앞서 이용한 parameterized statement 방식이 2번에 해당하는 방식이었다. )
그리고 SpringData의 mp911de 는
Statement.add().add() 를 이용해도 결국 왜 batch를 이용하지 못하는 이유를 묻는 질문에 대해 아래와 같이 답변 했다.
몇몇 DB의 드라이버들은 이전에 실행된 statement와 타입이 매칭 된다면, prepared statement 캐쉬를 이용하지만,
Postgres, SQL Server, H2, MariaDB의 경우에는 parametrized statement with a table of bindings을 이용 할 수 있는 API가 제공되지 않는다고 한다.
결국, 위에서 언급한 데이터베이스들을 이용 중이라고 한다면, 앞서 언급한 1번 방식, SQL을 직접 이어 붙이는 방식을 이용 해야 좋은 성능을 낼 수 있다는 것이다.
어떻게 구현했는지 알아보기 전에, 먼저 테스트 결과를 보고 갑시다!
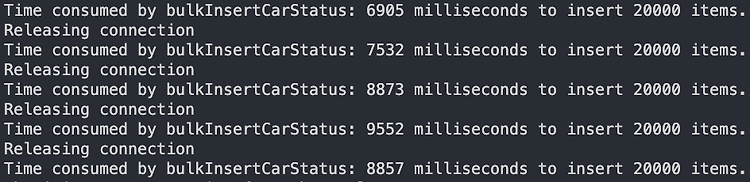
아래 결과는 버퍼 사이즈를 20,000건으로 총 100,000건을 INSERT 했을 때 걸린 테스트 결과입니다.
총 9,552ms이 걸린 것을 확인 할 수 있고, 처음 10,000건에 17초가 걸렸던 것을 기억한다면 약 17배 성능 향상이 있었음을 알 수 있습니다. (참고로 아래 정보는 Reactive로 실행되기에 가장 오래 걸린 건만 보면 됩니다.)

[Solved] 직접 쿼리 생성 함수 만들기
이제 원인은 알았고, 우리가 원하는 쿼리를 이어 붙이는 함수를 만들어줘야 합니다.
1) initSql 생성 함수
아래처럼 내가 원하는 Entity를 넘겨주면 해당 클래스가 가지고 있는 필드네임을 읽어서, 쿼리의 첫 시작 부분을 만들어 주는 함수를 만들었습니다.
public <T> StringBuilder getInitSql(Class<T> clazz)함수의 리턴 값은 아래와 같을 것입니다.
"INSERT INTO test_table(c1, c2, c3, c4) VALUES"
2) value concat 함수
이제, 저 initSql 뒤에 실제 값들을 이어 붙여서 쿼리를 만들어 봅시다.
public <T> StringBuilder generateBatchQuery(List<T> targetDatas, Class<T> clazz)
한번에 처리해도 되지만 targetDatas를 순환하면서 아래와 같은 generateQuery() 함수를 실행시켜 주는 방식으로 구현했습니다.
tableName은 사실 필요 없지만, 사내 규칙이 uuid + tableName을 이용하여 PK를 만드는 것이라 어쩔 수 없이 추가했습니다.
public <T> StringBuilder generateSingleQuery(String tableName, T data, Class<T> clazz)generateBatchQuery 함수 결과는 아래와 같을 것입니다.
"(v1, v2, v3, v4), (v5, v6, v7, v8);"
3) 주의할 점
사실 위 함수들을 만드는 로직자체는 크게 어렵지 않지만, 아래와 같은 주의 할 점들이 있습니다.
1. TypeCheck - SQL을 만들 때, primitive type(double, number, bigDecimal, boolean, etc)와 같은 타입들은 single quote를 붙이면 안되고, 나머지 타입에는 붙여줘야 합니다.
2. SQL Injection - 이런 방식으로 쿼리를 DB에 보내게 되면 SQL Inject에 취약할 수 있습니다. 저는 이를 예방하기 위해서 최소한의 조치인 HtmlUtils.htmlEscape(String input) 를 이용했습니다.
혹시 좀 더 제가 개선 할 수 있는 사항이 있거나, 궁금하신 점, 수정해야 할 내용이 있다면 댓글로 알려주시면 감사하겠습니다! 🙏
'java,springboot' 카테고리의 다른 글
| try-with-resources 사용법 및 주의점 (1) | 2023.12.05 |
|---|---|
| 브라우저에서 RTSP프로토콜 스트리밍 하기 (2) | 2023.10.30 |
| [Solved] Implicit super constructor Object() is undefined for default constructor. Must define an explicit constructor 에러 해결 (0) | 2023.06.13 |
| [WebFlux] saveAll(Iterable) vs saveAll(Flux) 뭘 써야 할까? (0) | 2023.05.23 |
| [Solved] DataBufferLimitException 보낼 때, 받을 때 둘 다 해결 (1) | 2023.05.22 |