
회사에서 서비스 현황을 한눈에 볼 수 있는 대시보드를 만들게 되었다.
이번 대시보드를 개발하면서,
- DB 쿼리 레벨의 집계와 설계
- YouTube 대시보드 요청 쿼리 구조
- 백엔드–프론트엔드 간 효율적인 네트워크 통신
- 실제 사용자 관점에서의 UX 개선
까지 한 번에 고민해볼 수 있었던 점이 매우 재밌었고, 유익한 경험이었기에 이를 기억하고자 또 공유하고 기록을 남긴다.
대시보드 요구 사항
처음 요구사항은 비교적 단순해 보였다.
- 달력을 통한 자유로운 기간 선택
- 집계 단위 선택 (Hour / Day / Week / Month / Year)
- 멀티 리전/여러 고객사(프로젝트) 지원
- 각 집계 단위마다 표출할 수 있는 데이터 최대 수량을 지정 할 수 있어야 한다.(e.g. 시간 단위 선택시 최근 24시간 표출)
그런데 꼭 기간 마다 표출할 수 있는 데이터의 최대 수량을 지정하는게 필요할까 라는 생각과, 만약 그렇게 표출하는 데이터의 최대 수량을 지정하게 되면 1번 요구사항과 상충된다고 생각이 들었다.
예를 들어, 내가 기간은 3년 + 집계 단위를 시간으로 설정하면, 실제로 보여주는 건 최근 24시간만 보여준다. 이상하다.
더군다나 대시보드 상단에 선택한 기간에 대한 Total Count가 표시되는 부분이 있는데, 차트는 최근 24시간, 상단 카드에는 선택한 기간 그대로 표시해야 하나? 라는 생각이 들었다. 이상하다.

그럼 그냥 데이터 전부를 보여주면 어떨까? 3년 선택하고 Day로 집계를 하게 되면 아래처럼 X축 라벨이 엉망으로 나오게 될 텐데...?

YouTube 대시보드 분석 - UX
우선 가장 먼저 떠오르는 고도화된 대시보드인 YouTube의 대시보드를 보기로 했다.

우선 먼저 문제 하나는 해결됐다.
"데이터를 다 보여주되, X축에는 가시성이 좋을 정도로만 Label을 표시하자"
따라서 요구사항 4번 부분을 빼기로 하고 총 3개의 요구사항을 만족시키는 대시보드를 구현해보기로 했다.
문득, 이 생각이 들었다.
"10년치의 데이터를 일별 집계로 들고 오면 어마어마한 데이터일텐데 이걸 YouTube는 어떻게 처리할까?"
YouTube 대시보드 분석 - Request/Response 구조
개발자 모드에서 Request와 Response를 까봤다.
아래 사진은 유튜브가 대시보드 화면을 구성하기 위해 보낸 요청의 Payload 구조이다.
내가 생각한 것과 너무 달랐다.
우선, 왜 nodes 배열로 관리를 할까? 왜 Object 형태가 가독성, 접근성 모두 좋을텐데? 라는 생각이 들었다.
그러나 아래 connectors를 보는 순간 그래프인가!? 라는 생각이 들었다.

connectors 부분만 잠깐 설명을 하자면,
extractorParams는 어떤 쿼리 노드의 결과에서 뭘 뽑아올지 정의하는 부분이고,
fillerParams은 뽑아온 값으로 어떤 노드의 쿼리/ID를 채울지 정의하는 부분 이다.
예를 들어, extractorParams의 2__TOP_ENTITIES_TABLE_QUERY_KEY 라는 쿼리 노드는 영상의 조회수, 조회 시간 등 각종 데이터를 테이블 형태로 나오는 쿼리이다. 그래서 이 테이블 결과에서 VIDEO 디멘션 값들(VIDEO ID) 추출해라. 라는 뜻이고,
fillerParams는 뽑아낸 VIDEO ID들을 2__TOP_ENTITIES_CHARTS_QUERY_KEY 조회할 때 채워라.
거기에도 { "dimension": { "type": "VIDEO" } }라고 되어 있으니까, 이 video ID들을 filller로 넣어라. 라는 뜻이다.
그랬다. YouTube는 한번의 요청으로 대시보드 화면을 구성하기 위해, 위와 같이 그래프 형태의 페이로드 구조로 요청을 보내고 있었다.
재밌다.
이제 응답 구조를 한번 보자.
앞서 요청 페이로드에 있었던 nodes 배열과 흡사하게 results 값 역시 배열로 구성되어 있다.
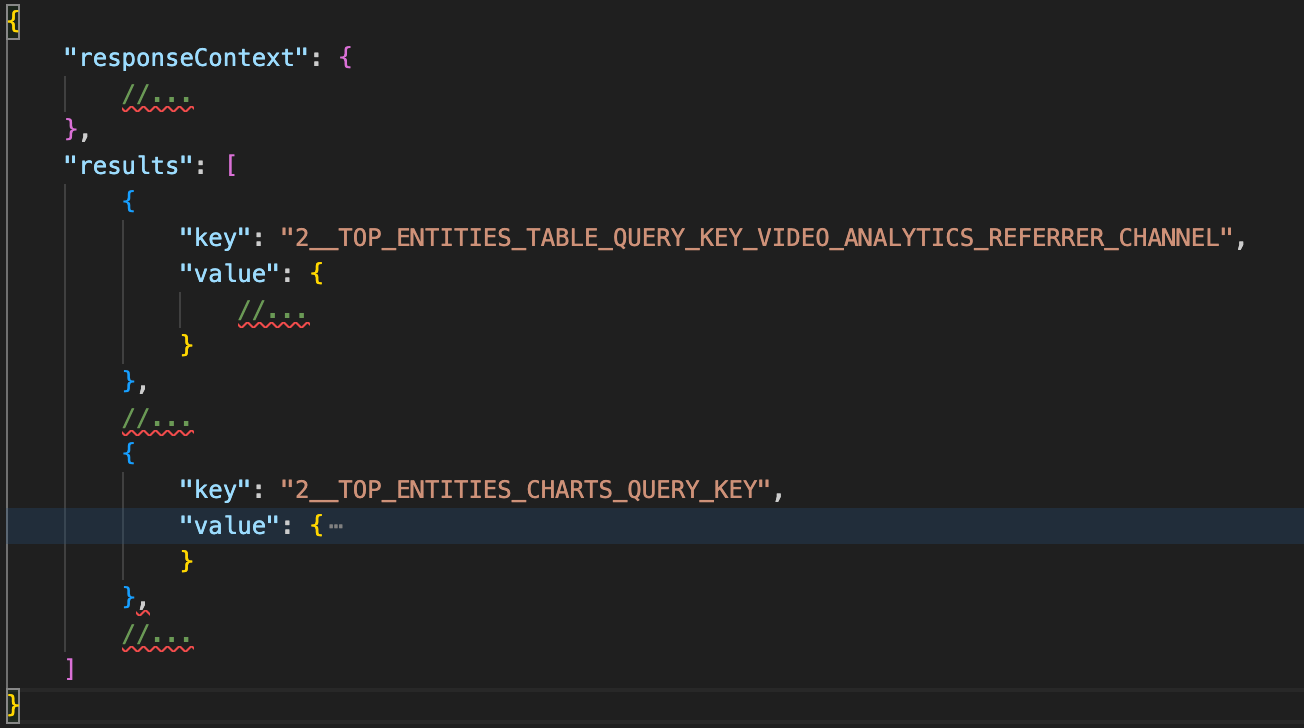
우리가 집중할 부분은 Chart 부분이니 차트 관련 쿼리만 자세히 보도록 한다.

해당 쿼리의 응답 구조는 크게 3부분으로 나누어져 있다.
dimensionColumns의 dateIds, dimensionColumns의 strings.values, metricColumns의 counts.values
- dimensionColumns는 내가 조회한 기간을 의미한다.
- dimensionColumns의 strings.values는 영상의 고유한 아이디 이다.
- metricColumns의 counts.values는 실제 조회수 이다.
즉, 각각의 0번째 Index 값들을 조회하면 20251128년도 Er... 영상의 조회수는 0이었다. 라는 것을 알 수 있다.
저 데이터 구조를 보니 차트에 바로 넣기 최적화된 구조라는 것을 알 수 있었다.
아! 프론트엔드 부하를 줄이기 위해 서버쪽에서 차트에 넣기 최적화된 구조로 파싱해서 내려주고 있구나. 라고 생각을 했다.
YouTube의 대용량 데이터 처리 방법
근데 문제점은 중복된 데이터들 이었다.
지금 나는 조회기간을 매우 짧게 영상도 1개에 대해 조회한 것이지만 만약 영상 100개, 3년간의 일자별 데이터를 조회하면?
그럼 데이터 칼럼 부분은 100개 * 3년 * 365 개의 어마어마한 중복된 데이터를 보내게 된다.
그럼 이런 네트워크 부하를 어떻게 줄이고 있을까?
결론적으로 YouTube는 Brotli라는 압축 기술을 쓰고 있다.
아래 사진에서 Content-Encoding: br 이라는 부분이 해당 응답은 Brotli로 압축해서 내려온 데이터다 라는 것을 보여주는 항목이다.
특히, Brotli는 더 큰 윈도우 사이즈를 활용해 중복된 데이터를 매우 효율적으로 압축할 수 있다는 점에서 강점을 가진 압축 알고리즘이다.

사실 부끄럽지만, Brotli는 처음 들어봤다.
하지만 당연히 gzip은 들어봤기에 두개의 압축기술을 비교하며 정리해봤다.

참고로 Brotli가 Gzip보다 압축효율이 15~20%정도 좋다.
특히나 중복된 데이터를 검사하는 윈도우 사이즈가 gzip보다 훨씬 크기 때문에 훨씬 효율적으로 압축을 진행할 수 있다.
사실 거의 모든 면에서 Brotli가 좋아보이지만, IE를 지원하지 않는다는 단점이 존재했다.
레거시한 환경에서 접속을 많이 하는 우리 제품 특성상 gzip을 사용하기로 했다.
KeyLink에서 2~3년간의 일자별 데이터를 조회 했을 때, 데이터의 크기가 일반적으로 gzip의 윈도우 사이즈(32kb)보다 작은 것을 확인했고, 크게 문제되지 않을 것이라 판단했다.
YouTube 분석 결과 및 적용 포인트
그래서 결론적으로 YouTube 대시보드를 분석/KeyLink에 적용한한 결과는 아래와 같았다.
- 프론트 엔드 부하 최소화
프론트에서는 최소한의 작업으로 차트 렌더링 할 수 있도록 서버가 가공된 데이터를 전달 해주고 있었다.
그래프 구조의 쿼리가 멋있어 보였지만, 현재 우리 제품의 레벨에서는 오버엔지니어링이란 판단을 내렸고,
우선, 프론트에서 바로 차트에 데이터를 넣어 렌더링 할수 있도록 아래처럼 구조를 설계하였다. - Brotli 와 같은 웹 압축기술 사용
앞서 언급한 것처럼 제품이 납품되는 사이트 특성상 gzip을 적용하기로 결정했다. - UI/UX 포인트
선택된 기간의 데이터를 전부 보여주되, 사용자가 보기 좋게 X축 라벨을 일부 생략하여 보여주기로 결정했다.

gzip 적용 및 성능 테스트
이제 gzip을 Spring서버에 application.yml에서 아래처럼 간단히 세팅했다.

- mime-types: 압축할 대상 타입을 지정
- min-request-size: 압축할 응답 최소 사이즈 지정
모든 응답에 대해 압축을 진행하게 되면 오버헤드가 더 커질 것이므로, min-request-size를 통해 1kb이상의 응답에 대해서만 압축을 진행하도록 세팅하였다.
이제 성능 테스트를 진행해봤다.
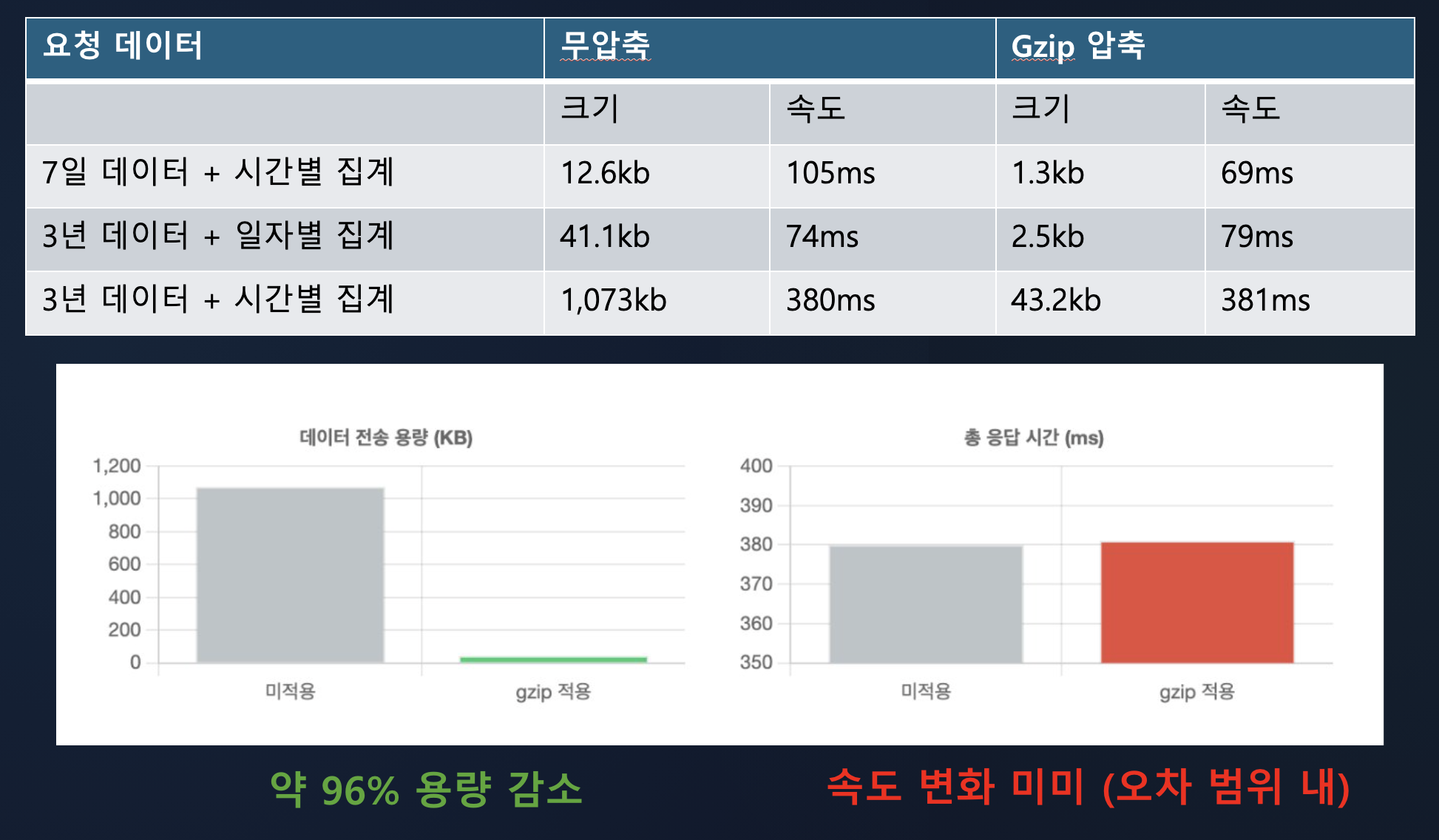
네트워크 전송 용량은 96%가 획기적으로 감소했다. 하지만 응답속도의 변화는 미미했다.
용량이 저렇게 획기적으로 줄었다는 것도 충분히 획기적인 성능 개선이지만, UX를 개선하고 싶었던 내 입장에선 조금 아쉬웠고 이유를 파고 들었다.
원인은 테스트 환경에 있었다. 테스트 진행시 로컬에 띄운 서버에서 테스트를 진행했고, 로컬에서 진행하다 보니 전체 소요시간에서 네트워크 전송시간이 차지하는 비율이 매우 작았다. 따라서 줄어든 네트워크 전송시간이 압축/해제 시간에 의해 상쇄됐던 것이다.

하지만, 일반적인 네트워크환경이나 조금만 안좋은 네트워크 환경에서는 그 시간이 획기적으로 줄어들 것으로 생각되며, 사실 네트워크 전송 데이터량을 96%나 줄이는 것만으로도 웹 압축기술은 반드시 도입해야할 기술이라고 생각이 된다.
집계 테이블 리팩토링 및 쿼리 최적화
이제 다음으로 집계 테이블에서 어떻게 데이터를 들고 오는지, 쿼리 레벨에서 분석했다.
기존 집계 테이블 구조엔 yy, mm, dd, hh, week와 같이 집계 시점을 저장하는 필드들이 있었다.
처음 설계하던 당시엔 Index만 제대로 걸어 놓는다면 어떤 시점의 데이터를 들고오기 좋은 구조라고 생각했다.

하지만, 기간 검색을 하다보니 문제가 생겼다.
저렇게 각 필드로 저장된 값을 조합해서 기간으로 검색하려고 하니 각 필드를 CONCAT해서 String을 비교 연산자를 통해 비교하게 되었다.
참고로 이런 경우 당연히 인덱스도 안탄다.
집계 기준시간을 event_time 이라는 필드에 저장하기로 했다.

참고로 해당 필드를 String으로 저장할지 datetime으로 저장할지 고민하다가
DATETIME 타입이 저장용량도 적을 뿐더러 비교할 때에도 String은 한글자씩 비교하지만, DATETIME은 숫자로 저장되기에 비교 속도마저 빠르기 때문에, 훨씬 적합한 필드 타입이라 생각이 되어 DATETIME 타입으로 결정했다.
UX 개선(feat. chart.js 커스텀 함수)
이제 마지막으로 UX 개선을 하기로 했다.
앞서 말한 것 처럼 아래 사진같은 현상을 막기 위해 기간에 맞춰 데이터는 다 보여주되, 가독성 좋게 몇개의 라벨만 보여주기로 했다.
Canvas에 기반한 Chart.js 라이브러리를 사용하고 있었는데,
다행히 해당 라이브러리에서 AutoSkip이라는 옵션을 제공해주고 있었다.
하지만, 항상 그렇듯 문제가 있었다. 마지막 라벨이 출력이 안된다.

찾아보니 라벨을 auto skip할 때 앞에서 하나씩 채워 나가기 때문에, 이런 문제가 생기며 chart.js의 고질적인 문제였다.
다행히 label을 렌더링 하는 callback 함수를 세팅하는 옵션을 제공해 주었기에 직접 구현하기로 했다.
우선 아래처럼 구현했다.
X축에서 최대 8개 정도의 라벨이 출력되도록 세팅하였고, 마지막 라벨과 그 직전 라벨이 겹치는 경우가 생겨 생략하는 로직까지 추가했다.

최종 회고
이번 대시보드를 구현하는 과정은 정말 즐거운 경험이었다.
특히 YouTube가 대용량 데이터를 어떻게 처리하는지, 왜 그런 복잡한 쿼리 구조와 응답 포맷을 선택했는지 하나씩 뜯어보는 과정이 무척 흥미로웠다. 이 프로젝트를 통해
- DB 쿼리 레벨의 집계와 설계,
- 백엔드–프론트엔드 간 네트워크 통신 구조,
- 실제 사용자 관점에서의 UX 개선
까지 한 번에 고민해볼 수 있었던 점이 개인적으로 큰 배움이었다.
무엇보다도 이 경험을 나만의 경험으로 끝내지 않고, 사내 동료들과 세미나 형식으로 공유한 것이 뜻깊었다. 발표를 통해 내가 설계한 방향이 타당한지 검증받을 수 있었고, 동시에 동료들이 제안해준 다른 관점과 아이디어를 접하면서 내가 미처 보지 못했던 부분도 새롭게 생각해볼 수 있었다.
이 대시보드 프로젝트는 단순한 기능 개발을 넘어, “좋은 구조란 무엇인가”를 함께 고민하고 성장할 수 있었던 소중한 경험으로 남았다.
'java,springboot' 카테고리의 다른 글
| [R2DBC] MariaDB Bulk Insert 성능 23배 개선: Driver의 한계를 넘자 (0) | 2025.11.26 |
|---|---|
| WebFlux 환경에서 레거시 Logging 시스템을 AOP 기반으로 리팩토링한 기록 (0) | 2025.04.13 |
| [Java] Java에서 JSON 다루기(mapper, converter) (0) | 2024.04.04 |
| [Springboot] Reactive Redis 총 정리(config, generic, test) (1) | 2024.02.06 |
| try-with-resources 사용법 및 주의점 (1) | 2023.12.05 |