
CS50에서 제공하고 있는 SQL강의를 듣고, 그 내용에 대해 정리하고자 한다.(강의링크)
Requirements
1. cs50 강의자료
강의에 필요한 자료들은 아래 링크에서 다운 받을 수 있다.
https://cs50.harvard.edu/sql/2023/weeks/0/
2. Sqlite3 터미널 포맷팅
sqlite3를 터미널에서 쓸 때 보기 편하게 하기 위해
아래처럼 세팅하자.
vi ~/.sqliterc
//아래 부분 추가 && wq
.mode box
.headers on
.separator ROW "\\n"
.nullvalue NULL
Database?
1. 데이터베이스 사용 이유
데이터들을 저장하고 관리하기 위해 엑셀과 같은 스프레드 시트가 아닌 데이터 베이스를 사용 했을 때 얻을 수 있는 이점은 아래 3가지를 들 수 있다.
- Scale: 많은 수의, 수 억개의, 데이터를 관리하기 위해서는 데이터 베이스 사용이 필수
- Frequency: 1초에 1000개씩 데이터가 들어오고 이를 저장 할 필요가 있다면, 데이터 베이스가 적합
- Speed: 원하는 정보를 찾고자 할 때, 빨리 찾을 수 있다.
2. 데이터베이스란?
그렇다면 데이터베이스란 무엇일까?
데이터 베이스는 데이터의 CRUD를 위해 잘 정리된 데이터의 집합을 의미한다.
3. DBMS, RDBMS(Relational DataBase Management System)란?
우리가 데이터베이스와 interact하게 도와주는 software를 의미한다.
대표적인 예로 MySQL, Oracle, SQLite 등이 있다.
DBMS와 어떻게 interact할 수 있을까? SQL이라는 것을 이용해서 할 수 있다.
4. SQL(Structured Query Language)?
데이터베이스와 interact, 즉 데이터를 CRUD 하기 위해 사용하는 언어를 의미한다.
SQL의 다양한 Keywords
1. SELECT
데이터베이스에 있는 데이터를 조회 할 때 사용하는 키워드이다. 아래와 같은 방식을 통해 데이터들을 조회 할 수 있다.
SELECT "title", "author"
FROM longlist;
테이블이름과 칼럼들에 대해서는 double quotes(”)를 사용하고, 스트링 타입에 대해서는 single quote(’)를 사용하는 것이 good practice && convention 이다.
2. LIMIT
너무 많은 데이터를 한번에 조회 하려고 하면 많은 시간이 소요 될 수 있다. 이럴 때 LIMIT을 사용해 주면 된다. 아래 쿼리는 출력되는 row의 개수를 10개로 제한한다.
SELECT "title"
FROM "longlist"
LIMIT 10;
3. WHERE
데이터를 조회 할 때 내가 원하는 조건을 설정 할 수 도 있다. 이때 사용 하는 것이 WHERE 키워드이다.
아래 예시를 보면 쉽게 사용 방법을 숙지 할 수 있다.
WHERE 키워드를 사용 할 때 다음과 같은 연산자들을 사용 할 수 있다.
- = (equal to)
- ≠ (not equal to)
- <> (not equal to)
SELECT "title", "author"
FROM "longlist"
WHERE "year" = 2023;
≠ 연산자와 <> 연산자는 같은 역할을 하므로, 아래 두 개의 예시는 같은 데이터를 조회한다.
SELECT "title", "format"
FROM "longlist"
WHERE "format" != 'hardcover';
SELECT "title", "format"
FROM "longlist"
WHERE "format" <> 'hardcover';
추가적으로 <> 연산자나 ≠ 연산자 대신 NOT 키워드를 사용 할 수도 있다.
SELECT "title", "format"
FROM "longlist"
WHERE NOT "format" = 'hardcover';
4. AND OR
여러개의 조건을 조합해서 사용 하고 싶을 때 AND와 OR 키워드를 사용 할 수 있다.
SELECT "title", "author"
FROM "longlist"
WHERE "year" = 2022 OR "year" = 2023;
SELECT "title", "format"
FROM "longlist"
WHERE ("year" = 2022 OR "year" = 2023) AND "format" != 'hardcover';
4. NULL
테이블안의 특정 칼럼에 대한 데이터가 없는 경우도 있을 수 있다. 이럴 때 데이터가 없는 것을 표시해주는 타입이 바로 NULL이다.
이 NULL 타입을 이용해서 데이터가 없는 데이터들을 조회 할 수도 있다.
NULL 타입과 함께 사용되는 조건절은 아래와 같다.
- IS NULL
- IS NOT NULL
SELECT "title", "translator"
FROM "longlist"
WHERE "translator" IS NULL;
SELECT "title", "translator"
FROM "longlist"
WHERE "translator" IS NOT NULL;
5. LIKE
특정 문자로 시작하거나 특정 단어를 포함한 데이터를 조회 할 때 사용하는 키워드가 LIKE이다. LIKE는 주로 아래와 같은 연산자들과 함께 사용된다.
- %(복수의 어떤 문자든 매치된다.)
- _(하나의 문자에 매치된다.)
[5-1. % 기호 활용법]
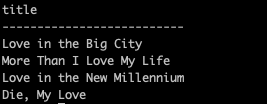
예를 들어, love라는 단어가 포함된 책 제목을 조회 하고 싶다면 아래와 같이 조회 하면 된다.
SELECT "title"
FROM "longlist"
WHERE "title" LIKE '%love%';
그럼 아래와 같이 love가 포함된 책 제목들이 나올 것이다.
만약 love로 시작되는 책 제목을 조회 하고 싶다면 아래처럼 쿼리를 작성하면 된다.
SELECT "title" FROM "longlist" WHERE "title" LIKE 'love%';
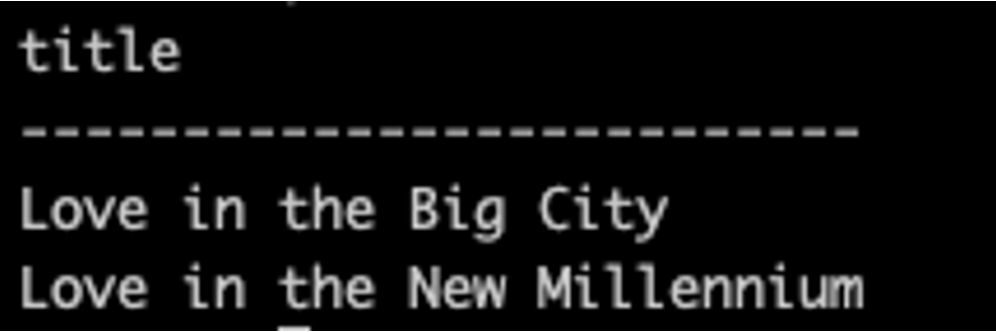
[5-2. 특정 단어로 시작하는 데이터 조회]
근데 저렇게 조회하면, love로 시작하는 제목 뿐만 아니라, lovat, lovability 와 같은 제목들도 함께 조회 될 것이다.
이럴 때 띄어쓰기를 해주면 된다.
SELECT "title" FROM "longlist" WHERE "title" LIKE 'love %';
[5-3. 대소문자 구분 데이터 조회]
조회된 결과들을 보면 대소문자 구분이 안되고 있다.
이는 SQLite에서 LIKE는 대소문자 구분을 하지 않기 떄문이다. 만약 SQLite에서 대소문자 구분을 하여 데이터 조회를 하고 싶다면
= 연산자를 사용하면 된다.(데이터 베이스마다 다르다. mysql도 대소문자 구분을 하지 않는다.)
만약 mysql에서 like로 대소문자 구분을 하고 싶다면 바이너리로 검색을해주어야 한다.
이는 바이너리로 된 테이블의 경우 대소문자를 구분하여 검색하기 때문이다. 구체적인 방법은 아래와 같다.
SELECT * FROM [table_name] WHERE BINARY([field_name]) LIKE '%some%';
[5-4. _ 기호 활용법]
% 기호는 문자가 몇 개가 오든 상관하지 않고 매치가 되지만, _ 기호는 딱 한개의 문자와 매치가 된다.
예를 들어, T로 시작하는 4글자의 책 제목을 조회하고 싶다면 아래와 같이 조회 할 수 있다.
SELECT "title" FROM "longlist" WHERE "title" LIKE 'T___';
언더바 4개를 한 경우에는 매치되는 케이스가 없어, 조회된 데이터가 없고, 언더바 3개인 경우에만 데이터가 조회되는 모습을 볼 수 있다.

6. Ranges(Between) - 범위 조회
범위조회를 하기 위해 WHERE과 함께, 앞서 살펴봤던 연산자들(<,>,≤,≥)도 사용 할 수 있다.
SELECT "title", "author"
FROM "longlist"
WHERE "year" >= 2019 AND "year" <= 2022;
위의 쿼리를 BETWEEN과 AND 키워드를 통해서도 조회 할 수 있다.
SELECT "title", "author"
FROM "longlist"
WHERE "year" BETWEEN 2019 AND 2022;
SQLite와 Mysql 에서 Between은 이상이하로 조건이 설정 된다.
[6-1. 날짜 범위 조회시 주의할 점]
주의할 점은 datetime으로 저장된 데이터를 날짜로 조회할 때, 시간까지 명시해줘야 한다는 점이다.
이와 같은 원리로 date타입으로 저장된 데이터를 년과 월로만 조회 하면 원하는 대로 조회되지 않는다.
이는 시간은 기본적으로 00:00:00으로 설정되고, 날짜는 01으로 설정되기 때문이다.
아래 쿼리는 8월과 9월의 책 제목을 모두 리턴해줘야 할 것 같지만(이상, 이하 이므로) 결과는 8월만 리턴된다.
SELECT "title", "published" FROM "longlist"
WHERE "published" BETWEEN '2017-08' AND '2017-09';

따라서 이렇게 날짜를 조회 할 때에는 하위단위까지 명시해주는 것이 중요하다.
SELECT "title", "published" FROM "longlist"
WHERE "published" BETWEEN '2017-08-01' AND '2017-09-30';

7. ORDER BY - 정렬
데이터를 정렬해서 조회 하고 싶을 때가 있다.
예를 들어, 평점 탑 10을 조회 하고 싶을 때이다. ORDER BY와 LIMT를 이용해서 원하는 대로 정렬 할 수 있으며 정렬방법은 아래와 같다.
- ASC(오름차순)
- DESC(내림차순)
기본적으로 default 값은 ASC(ascending), 즉 오름차순이다. 아래 예를 살펴보자.
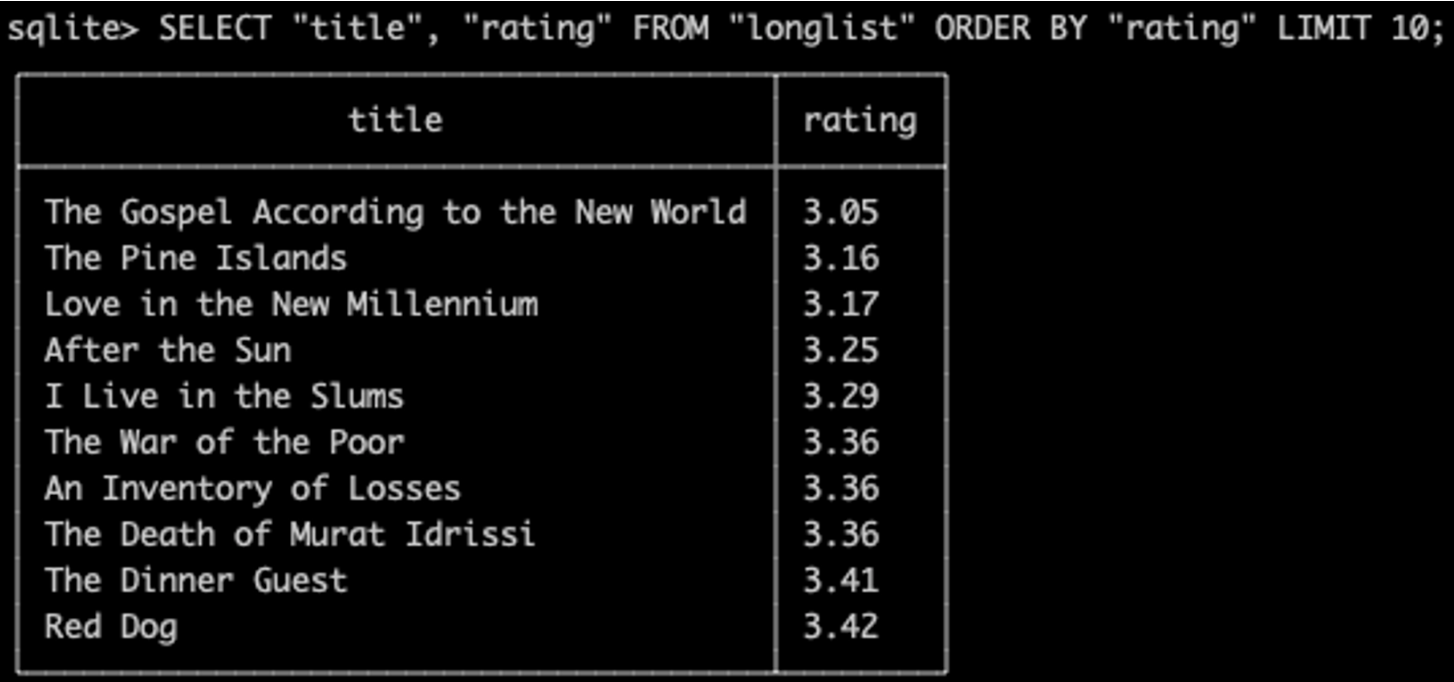
아무 조건 없이 ORDER BY를 이용해서 정렬 했을 때, 평점이 낮은 순 부터 높은 순으로 정렬 되는 것을 볼 수 있다.
SELECT "title", "rating" FROM "longlist"
ORDER BY "rating" LIMIT 10;
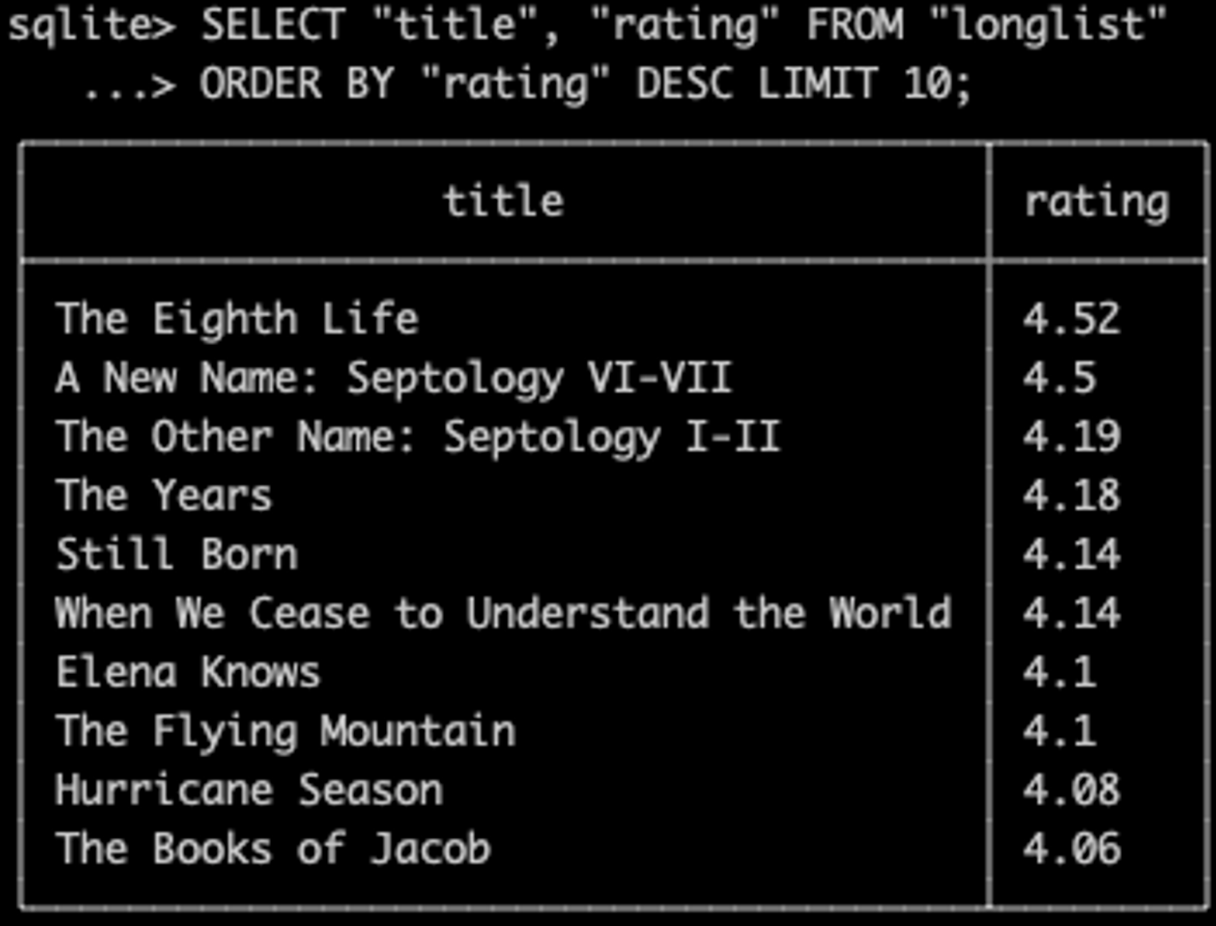
그럼 정렬방법을 내림차순(DESC)으로 명시하여 탑 10 책 제목을 조회 해 보자.
SELECT "title", "rating" FROM "longlist"
ORDER BY "rating" DESC LIMIT 10;
[7-1. 여러 조건으로 정렬]
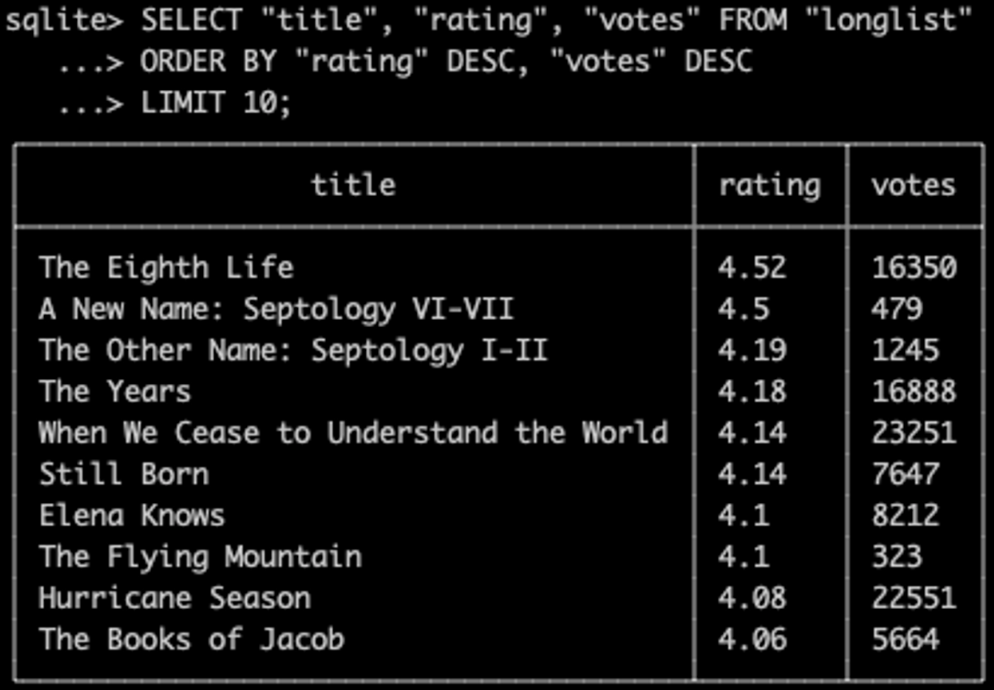
그런데, 평점이 4.14로 동점인 케이스가 보인다. 이럴 때 투표수를 기준으로 정렬 하고 싶다면 어떻게 해야 할까?
‘,’를 이용해 rating으로 먼저 정렬하고, 그 뒤에 votes를 2순위로 정렬 하도록 할 수 있다.
SELECT "title", "rating", "votes" FROM "longlist"
ORDER BY "rating" DESC, "votes" DESC
LIMIT 10;
알파벳 순서로 정렬 할 때에도 ORDER BY를 사용 할 수 있다.
Aggregate Functions - 집계함수
데이터를 통계 내는 것을 도와주는 집계함수라는 것이 있으며 대표적으로 아래 5가지가 있다.
- COUNT - 데이터들의 개수를 카운트 해주는 함수
- AVG - 데이터들의 평균 값을 구하는 함수
- MIN - 데이터들의 최소 값을 구하는 함수
- MAX - 데이터들의 최대 값을 구하는 함수
- SUM - 데이터 값들을 합산 값을 구하는 함수
각 함수의 사용 예시는 아래와 같다.
참고로, DISTINCT 키워드를 사용하면 중복된 값들을 제외하고 카운트 할 수 있다.
SELECT AVG("rating")
FROM "longlist";SELECT ROUND(AVG("rating"), 2)
FROM "longlist";SELECT ROUND(AVG("rating"), 2)AS "average rating"
FROM "longlist";SELECT MIN("rating")
FROM "longlist";SELECT MAX("rating")
FROM "longlist";SELECT COUNT(*)
FROM "longlist";SELECT COUNT("translator")
FROM "longlist";SELECT COUNT(DISTINCT "publisher")
FROM "longlist";'SQL' 카테고리의 다른 글
| [CS50 - SQL] Lecture 1 - Relating(join, pk, fk) (0) | 2023.10.16 |
|---|