
CS50에서 제공하고 있는 SQL강의를 듣고, 그 내용에 대해 정리하고자 한다.(강의링크)
Relations
하나의 데이터베이스는 여러 개의 테이블을 가질 수 있고, 각 테이블들은 관계를 가질 수 있다.
이러한 테이블들간의 관계는 아래 중 하나로 표현 될 수 있다.
- 1:1관계
- 1:N관계
- M:N관계
예를 들어 간단히 설명해 보자.

한 명의 작가가 하나의 책만 쓸 수 있다면, ➡ 작가와 책은 1:1관계를 가질 것이다.

한 명의 작가가 여러 개의 책을 쓸 수 있다면, ➡ 작가와 책은 1:N의 관계를 가질 것이다.

하나의 책은 여러 명의 작가가 함께 집필 할 수도, 한 명의 작가가 여러 개의 책을 쓸 수도 있다면 ➡ M:N의 관계를 가질 것이다.
Entity Relationship Diagrams(ERD) - 테이블 관계 표현
위와 같은 관계는 아래의 ERD라는 것을 통해 간단히 표현될 수 있다.

위 ERD에서 각 테이블을 이어 주는 라인들은 아래와 같은 의미를 가지고 있다.

위 ERD에서 Translator와 Book간의 관계를 예를 들어 보자.
위 ERD에 따르면 한 개의 책에 Translator는 없을 수도, 혹은 여러 명일 수 있다.
또한 한 명의 Translator는 최소 한 개 이상의 책을 번역할 수 있다.
따라서 Translator와 Book 테이블은 M:N의 관계를 가지고 있다.
마지막으로 Publihser와 Book의 관계를 살펴보자.
한 개의 책은 한개의 publisher를 반드시 가지고 있어야 한다.
하나의 publisher는 최소 한개 이상의 책을 publish 할 수 있다.
따라서 Publihser와 Book 테이블은 1:N의 관계를 가지고 있다.
이렇듯, ERD를 통해 복잡한 테이블간의 관계를 표현 및 파악할 수 있다.
Keys
1. Primary Keys
테이블에서 각 레코드를 유니크하게 식별 할 수 있는 값을 의미한다.
따라서, PK는 NULL이 될 수 없다는 특징을 가지고 있다.

각 책들이 ISBN이라는 고유한 identifier가 있다고 한다면, ISBN은 Book 테이블의 PK가 될 수 있을 것이다.
2. Foreign Keys
테이블간 관계 설정을 하는데 사용되는 키이다.
외래키는 다른 테이블의 PK이다. 다른 테이블의 PK를 레퍼런싱함으로써, 각기 다른 테이블간에 관계를 만들 수 있다.
[2-1. 1:N 관계 설정]
1:N의 관계는 FK를 이용해 아래처럼 설정 할 수 있다.

위 사진을 통해 books의 PK인 isbn이 ratings 테이블의 FK로 설정된 모습을 볼 수 있다.
이제 books와 ratings는 1:N의 관계를 가지게 된다.
[2-2. M:N 관계 설정]
그렇다면 M:N의 관계는 어떻게 설정할 수 있는지 알아보자.

다대다 관계를 구현하기 위해서는 보통 연결테이블(junction table)을 만들어 준다.
위 사진에서는 authored 테이블이 연결테이블이 된다.
Subqueires
nested queries라고도 불리는 서브쿼리는 쿼리 안에 있는 쿼리를 의미한다.
books와 publishers가 1:N의 관계를 가지고 있다고 하였을 때, 아래 예시를 살펴보자.
우선 우리가 작성할 쿼리의 목적은 Fitzcarraldo Editions이 발간한 책들의 제목을 찾는 것이다.
books테이블은 아래처럼 생겼다.

즉, books 테이블 안에서 바로 publisher가 Fitzcarraldo Editions인 데이터들을 찾을 수 없고, Fitzcarraldo Editions의 publisher_id를 찾은 뒤에야 해당 출판사가 발간한 책 제목들을 찾을 수 있다.
이때 subquery를 이용 할 수 있다. 아래 쿼리 예시를 살펴보자.
()안에 있는 subquery가 먼저 실행 되어서 우리가 원하는 publisher의 id를 가져 온 뒤, 그 id를 이용하는 바깥쪽에 있는 쿼리가 실행되게 된다. (물론, subquery 대신 join을 사용할 수도 있지만 이 부분은 아래에서 살펴보자.)
SELECT "title"
FROM "books"
WHERE "publisher_id" = (
SELECT "id"
FROM "publishers"
WHERE "publisher" = 'Fitzcarraldo Editions'
);
IN
원하는 value가 value lists안에 있는지 확인 할 때 사용하는 키워드이다.
역시나 예를 들어보자.
우리가 작성할 쿼리의 목적은 ‘Fernanda Melchor’라는 작가가 쓴 책들의 제목을 출력하는 것이다.
참고로, Fernanda Melchor는 총 2개의 책을 썼다.
즉, 연결테이블인 authored에서 찾은 book_id는 아래처럼 총 2개가 나오게 된다는 것이다.

우리는 이제 books테이블에서 2개의 book_id와 일치하는 id를 가진 "books.title"을 찾아야 한다. WHERE을 사용하면 될 것 같기는 한데, 지금까지 배운 = 연산자나 LIKE 등은 우리가 원하는 작업을 하지 못한다. 이때 사용할 수 있는 것이 IN 키워드 이다.
최종 쿼리는 아래처럼 될 것이다.
SELECT "title"
FROM "books"
WHERE "id"IN (
SELECT "book_id"
FROM "authored"
WHERE "author_id" = (
SELECT "id"
FROM "authors"
WHERE "name" = 'Fernanda Melchor'
)
);
JOIN
2개 이상의 테이블을 결합하는데 사용되는 키워드이다.
역시 아래 예를 보면서 이해해 보자. 예시 테이블은 아래와 같다.

나는 sea linon들의 이름과 이들이 몇 일동안 얼마나 이동했는지 확인하고 싶다.
즉, id, name, distance, days를 함께 보고 싶은 것이다. 이럴 때 우리는 JOIN 키워드를 사용할 수 있다.
SELECT *
FROM "sea_lions"
JOIN "migrations"ON "migrations"."id" = "sea_lions"."id";
JOIN을 하기 위해서는 두 테이블간 공통적으로 가지고 있는 common facotr를 조건으로 걸어줘야 한다.
위 예시에서는 sea_lions.id와 migrations.id가 여기에 해당된다.
- ON: 매칭 조건을 명시할 때 사용된다. 즉, 어떤 common factor를 기준으로 매칭시킬지 명시하는 키워드이다.
- JOIN: INNER JOIN이 default이다.
1. INNER JOIN
INNER JOIN은 매칭되는 데이터들만 보고 싶을 때 사용된다.앞서 살펴본 테이블을 잠시 다시 보자.
sea_lions 테이블에는 총 6개의 바다사자들이 있지만, migrations에는 총 8개의 바다사자들이 있다.
여기서 주의해서 볼 점은 Jolee라는 바다사자는 sea_lions테이블에는 있지만, migrations테이블에는 존재하지 않는다는 점이다.
반면, migrations에 있는 11735, 11736, 11737은 sea_lions 테이블에 존재하지 않는다.
이때, INNER JOIN을 사용하면 두 테이블에서 공통으로 존재하는 바다사자들만 보여주게 된다.

2. LEFT (OUTER) JOIN
INNER JOIN 과 상대되는 개념으로 OUTER JOIN이라는 것이 있고, OUTER JOIN에는 총 3가지의 JOIN이 있다.
- LEFT JOIN
- RIGHT JOIN
- FULL JOIN
RIGHT와 FULL JOIN은 방향만 다를 뿐이니, LEFT JOIN에 대해서만 정리하자.
참고로 JOIN 앞에 오는 테이블이 LEFT TABLE, JOIN 뒤에 오는 테이블이 RIGHT 테이블이다.
앞서 다룬 예시에서 sea_lions가 left, migrations가 right 테이블이 될 것이다.
LEFT JOIN을 하게 되면, JOIN할 때 기준을 LEFT로 둔다는 것이다. 예를 통해 살펴보자.
SELECT *
FROM "sea_lions"
LEFTJOIN "migrations"ON "migrations"."id" = "sea_lions"."id";
위 쿼리는 sea_lions에 있는 모든 데이터들을 보여주되, Jolee라는 바다사자는 migrations테이블에 없기 때문에, NULL 값으로 출력된다. 아래 사진에서 Jolee 부분을 주의해서 보자.

RIGHT와 FULL도 같은 메커니즘이다..
RIGHT는 오른쪽 테이블을 기준으로, FULL은 두 테이블 모두를 기준으로 출력한다.
SETS OPERATOR
SQL에는 집합 개념을 활용한 UNION, UNION ALL, INTERSECT, EXCEPT 연산자가 존재한다.
각 연산자가 의미하는 바를 집합으로 표현하면 아래와 같다.
1. INTERSECT - 교집합
SELECT "name"FROM "translators"
INTERSECT SELECT "name"FROM "authors";
2. UNION - 합집합
SELECT "name"FROM "translators"
UNION SELECT "name"FROM "authors";
2. EXCEPT - 차집합
SELECT "name"FROM "authors"
EXCEPT SELECT "name"FROM "translators";
Groups
어떤 데이터를 조회할 때, 그룹으로 묶었을 때 그 의미가 더 유의미해질 때가 있다.
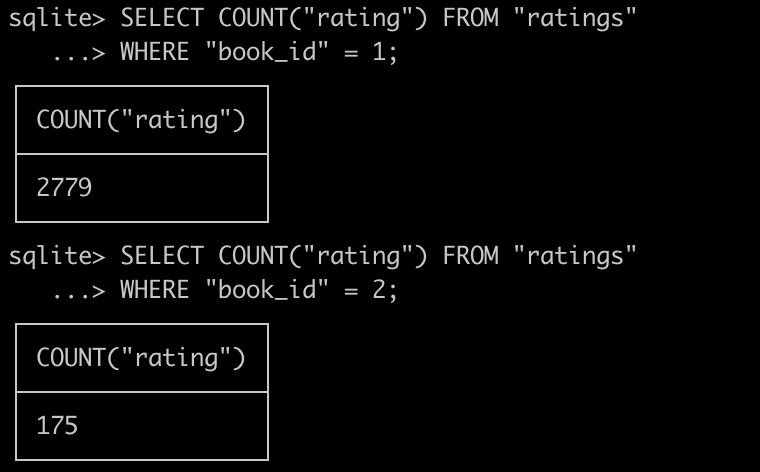
책들의 평점을 구하는 경우를 생각해보자.
아래 쿼리를 통해 알 수 있듯이, 각 책 아이디마다 상당한 개수의 평점들이 데이터베이스에 저장되어 있다.
이 값들은 book_id로 묶은 뒤, 평점을 냈을 때 유의미한 데이터가 될 것이다.
한 발자국 더 나아가 평점 4점이상의 책들의 평점을 구해보자.
아래처럼 GROUP BY를 이용하면서 조건을 걸고 싶다면 WHERE가 아닌 HAVING을 사용해주어야 한다.
SELECT "book_id", ROUND(AVG("rating"), 2)AS "average rating"
FROM "ratings"
GROUP BY "book_id"
HAVING "average rating" > 4.0;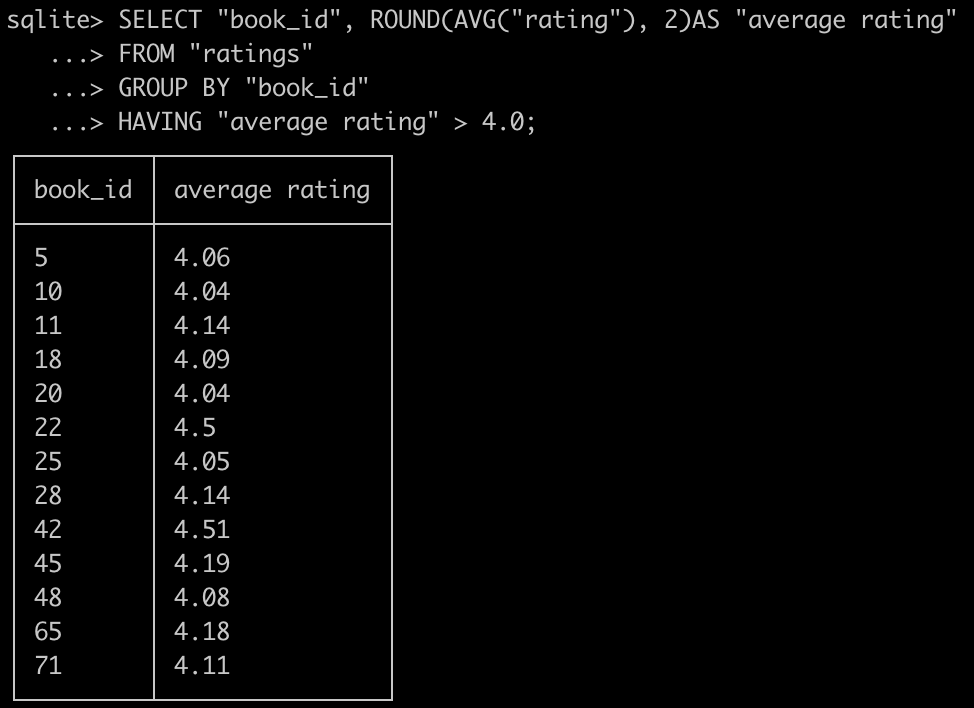
'SQL' 카테고리의 다른 글
| [CS50 - SQL] Lecture 0 - Querying (1) | 2023.10.13 |
|---|